Let's Spark Some Components
Imagine Spark as an intricate board game with many pieces, all working in a strategic way to… process big amounts of data seamlessly. Sounds fun, right? Well, maybe not as fun as Carcassone, but bear with me.
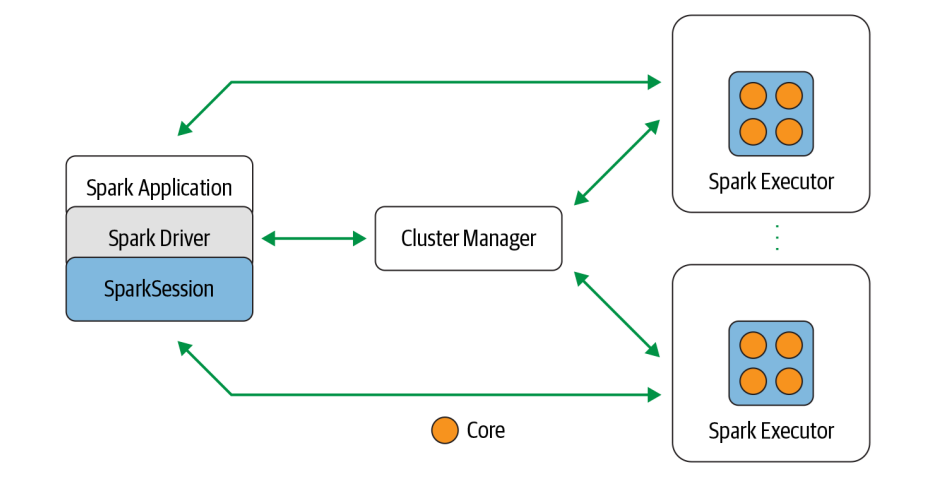
Today, let’s break down Spark’s key components and see how they interact with each other to create this harmonic framework. And to help visualize it, check out this beautiful picture:
 Source: Damji, J. S., Wenig, B., Damji, J. S., Das, T., Lee, D. (2020). Learning Spark: Lightning-fast Data Analytics. Estados Unidos: O’Reilly Media.
Source: Damji, J. S., Wenig, B., Damji, J. S., Das, T., Lee, D. (2020). Learning Spark: Lightning-fast Data Analytics. Estados Unidos: O’Reilly Media.
The protagonist
Our protagonist here is the Spark Driver, a brilliant tactician always in control, orchestrating the grand ballet of data processing. It is responsible for instantiating a SparkSession, comunicating with the Cluster Manager to request ressources (like compute power or memory) for the Spark Executors, transforming all Spark operations into DAGs, scheduling the DAGs and distributing their execution as tasks directly to the Spark Executors.
The toolkit
If the Spark Driver was Batman, then the SparkSession is its utility belt equipped with all the essential gadgets to get the job done.
In other words, whenever you write a Spark Application (like a piece of code), it usually starts by creating a SparkSession. This session is your entry point to interact with Spark functionalities, like managing contexts and creating and manipulating DataFrames and Datasets, that are the main tools you’ll use to work with your data.
The Logistic Manager
The Cluster Manager manages and allocates the ressources and helps the Spark Driver to get everything in order on different machines in the cluster.
Popular Cluster Managers include YARN, Mesos, and Kubernetes, but Spark also comes with a built-in Standalone Manager if you’re keeping things simple.
The whole team together
And with that, we delved into the intricacies of Spark Architecture, unraveling its core components. Putting it all together:
When you submit a Spark job:
- the Spark Driver communicates with the Cluster Manager to request resources.
- The Cluster Manager assigns the necessary resources to different Executors.
- The Executors, who runs on each worker node on the cluster, carry out the tasks given by the Spark Driver, while Cluster Manager keeps track of everything to make sure the work is done efficiently through the SparkSession.
Still Confused?
If this feels like trying to learn the rules of a heavy boardgame in one sitting — don’t worry, hopefully it will get easier.
For now, go forth and Spark some data!